In what may prove to be a significant milestone in High Performance Computing (HPC), researchers with HiDALGO2 have demonstrated the potential of a new code called Xyst to run efficiently on almost 200,000 CPU cores in parallel.
While further validation is necessary, early results are promising and indicate that Xyst may allow certain complex modelling tasks to be accomplished far quicker than at present, opening new avenues for research across multiple fields.
Modern engineering simulations, such as those used to model turbulent airflow around vehicles or structures, are vital for industries ranging from automotive design to aerospace. Yet these simulations are often constrained by the time they take to compute.
Supercomputers such as LUMI (currently the largest supercomputer in Europe, located in Finland) are vital to allowing such simulations to take place at a reasonable timescale. Yet the large number of CPU cores (a total of 362,496 for LUMI) are only part of the story. For these to be used effectively, new computational codes are needed that can make effective use of such large numbers of cores in parallel.

Current computational fluid dynamics (CFD) codes typically stop scaling efficiently after a few hundred, or thousand cores. A key challenge is therefore to develop such codes that show high scalability, with processing time dropping proportionally to the number of cores used, even as these reach the hundreds of thousands.
This is a key issue researchers at the Mathematical Simulation and Optimization Research Group of Széchenyi István University, Hungary, a HiDALGO2 partner are seeking to address with Xyst.
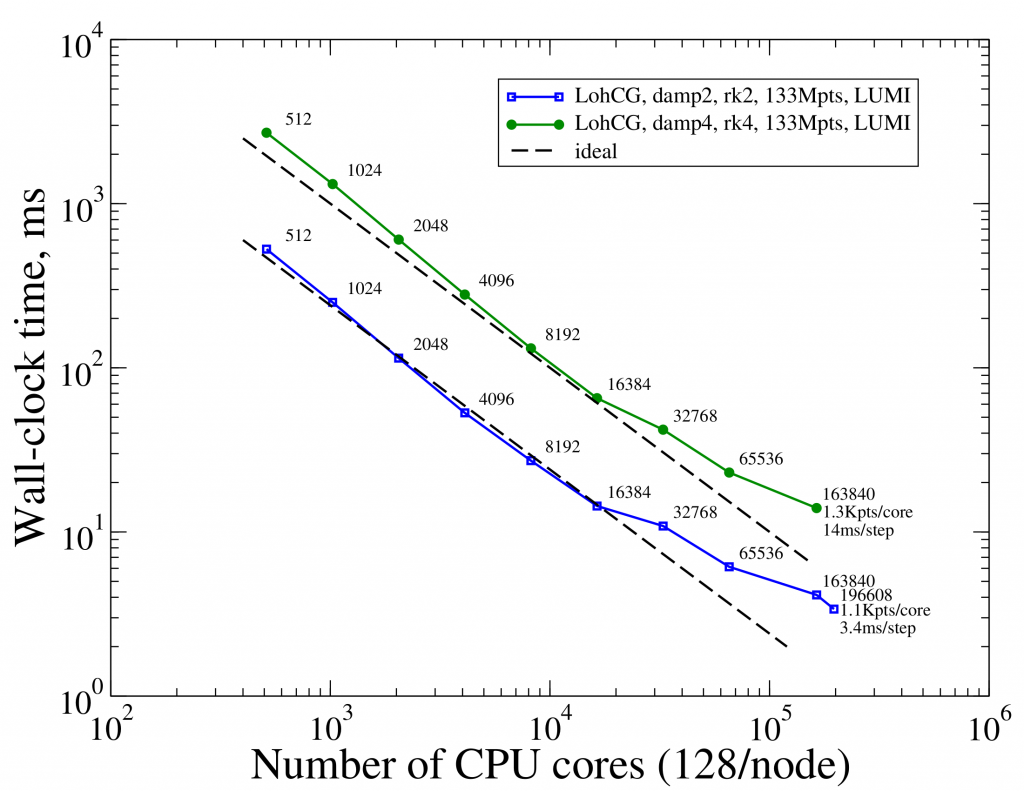
And recent results are highly promising: in a series of recent “hero runs” on LUMI, Xyst demonstrated high scalability, operating successfully on up to 196,608 cores, without running into any significant bottlenecks.
A second important result concerns the solvers used in the experiment, specifically one dubbed LohCG. This solver specialises in simulating incompressible flows in complex geometries, such as those encountered in engineering applications. The key finding here is that at 196,608 CPU cores, a single time step (the interval between changes in a simulation) took just 3.4 milliseconds with well above hundred million numerical degrees of freedom characteristic of simulation fidelity and accuracy. Further, the solver had not stopped scaling at this point indicating that with additional cores, performance could be even better.
Jozsef Bakosi, who led the work writes, “The reason why this result is important is because such a solver could be used in engineering practice in a way that allows a fundamentally different engineering workflow compared to existing practice. For example, current large-scale simulations that would be required to compute the turbulent flow around a passenger car would require 2-3 weeks to compute with current codes independent of the size of the computers (that’s mainly because the codes stop scaling at a few hundred, perhaps max a thousand, CPU cores and thus they don’t get faster with more CPUs) […] With Xyst such a single simulation could be done in 1-2 days. Consequently, this may provide a paradigm shift in how engineers could use such a tool and would make the currently impossible possible.
“I am making this claim based on the quantitative figure of ~4ms/timestep wall clock time and the fact that the solver has not stopped scaling at 200K CPUs. One could potentially throw more resources to larger problems with roughly constant turnaround times. This is crucially important and, as far as I know, this does not exist in engineering practice in industry, resolving complex flow boundaries to such accuracy.”
Technical Excellence Backed by a Decade of Development
The Xyst code has its roots in Quinoa, an earlier HPC framework developed over a decade ago at Los Alamos National Laboratory. About two years ago Xyst was forked from Quinoa and has evolved to include specialized solvers, rigorous testing, and significant simplifications to improve usability and performance. Similar to Quinoa, Xyst relies on the Charm++ runtime system for parallelism, a key factor in its success at scale.
Unlike traditional MPI-based codes, Charm++ offers higher-level programming abstractions and built-in features such as automatic load balancing and asynchronous execution. These capabilities allow Xyst to seamlessly combine data and task parallelism while hiding latencies, ultimately boosting performance. This advanced architecture has enabled Xyst to tackle challenges such as memory-efficient parallel mesh partitioning and effective CPU utilization during execution of the LUMI runs.
Results That Inspire Confidence
During the LUMI hero runs, Xyst demonstrated strong scaling for three solvers, including the LohCG solver. The test cases confirmed that the code was free from bottlenecks in both computation and input/output (I/O) performance, even at massive core counts. Quantitative details, available on the Xyst website, illustrate the scalability and efficiency achieved for the RieCG, ZalCG and LohCG solvers.
While these results are promising, Bakosi notes that Xyst is not yet ready for widespread industrial application. The recent tests were conducted on an academic (simple) verification problem. Future work will focus on validating Xyst with real-world geometries, such as turbulent flow simulations in complex engineering geometries.
This article was written by Pavlos Zafiropoulos of Future Needs in collaboration with Jozsef Bakosi of the Mathematical Simulation and Optimization Research Group of Széchenyi István University, Hungary.