Hardware acceleration, especially through Graphics Processing Units (GPUs), is vital for enhancing computational speed and efficiency. GPUs are designed for parallel processing, enabling them to handle multiple data sets simultaneously. This makes them highly efficient at rendering graphics, image processing, and machine learning tasks. In contrast, CPUs process operations sequentially, making GPUs faster at computations. Furthermore, GPUs are more adept at performing mathematical calculations, which is crucial in scientific computing and machine learning that require quick processing of large data volumes.
However, due to market segmentation, many accelerators (e.g., GPUs) suffer from language lock-ins (e.g., CUDA), restricting the use of the same language across multiple vendor accelerators. This limitation increases development costs and undermines developer productivity [1].
To address these issues, various alternatives have emerged, such as OpenCL, SYCL, or OpenMP. These languages can run on multi-vendor accelerators such as CPUs or GPUs while using the same code.
CFDs, or Computational Fluid Dynamics, is a branch of fluid mechanics that uses numerical analysis and algorithms to solve and analyze problems involving fluid flows. It is used to predict fluid flow, heat transfer, mass transfer, chemical reactions, and related phenomena. Forexample, in the HIDALGO2 project CFDs are used as study cases to test innovative High-Performance Computing (HPC) technologies.
Due to the parallel processing capabilities of GPUs make them well-suited for the large-scale, intensive computations required in CFD analysis. Each point in a fluid grid can be calculated simultaneously, leading to a substantial decrease in computation time. This is particularly beneficial in real-time simulations where results are needed quickly. However, this facet remains relatively unexplored [2].
Environment
For the experimentation, we will employ three GPUs from three main vendors:
Utilizing these three GPUs, we will compare the native languages (CUDA for NVIDIA, HIP for AMD, and Level0 for Intel) with the two selected multi-vendor languages (OpenMP and SYCL).
Concerning the benchmarks or tests, we utilized a set of eleven CFD cases, incorporating standard CFD equations. A more comprehensive examination of each benchmark and its input parameters is provided in the repository linked after this blog.
Experimental Results
The following figures show the time obtained for each CFD benchmark, obtained by running them 10 times. The bar represents the average time, with error bars indicating the standard deviation. The y-axis is presented in a logarithmic scale, as each test differs significantly in time scale. It’s important to note that in a logarithmic scale, small differences actually correspond to substantial differences in an ordinary scale.
Reviewing Figure 1 for the Tesla V100, CUDA serves as the native language. Notably, CUDA failed in the heat2d test, SYCL in heat2d and miniWeather, and OpenMP in the d3q19-bgk and lid-driven-cavity tests. However, it’s worth noting that d3q19-bgk is not part of the original suite, so technically, it’s a missing benchmark across CUDA and OpenMP, and two failed benchmarks for SYCL.
SYCL averaged 90% of CUDA performance, while OpenMP reached 89%. Depending on the benchmark, these percentages may vary slightly.
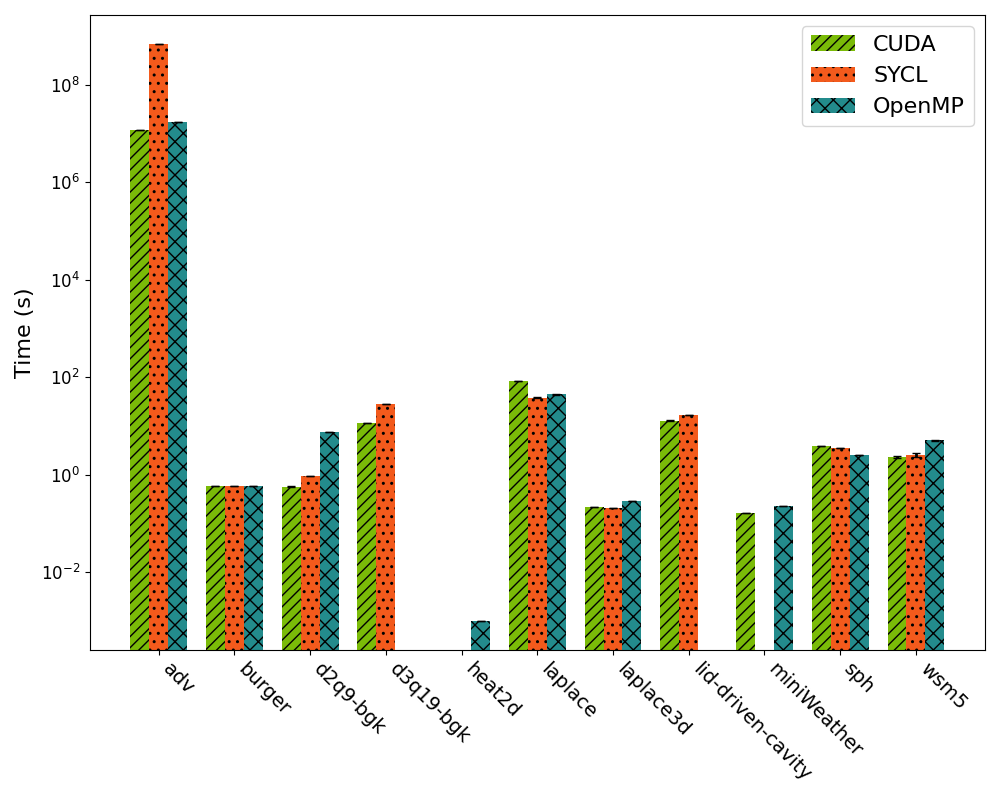
Figure 1: NVIDIA Tesla V100 performance comparison across CUDA, OpenMP, and SYCL.
Figure 2 shows results from the AMD 6700 XT. The native language for AMD GPU is HIP. While both HIP and SYCL ran all benchmarks, OpenMP failed the lid-driven-cavity test.
The results show poor performance on AMD architecture. OpenMP achieves only 51% of HIP times on average, while SYCL reaches up to 66% of native performance. The standard deviation (SD) for OpenMP is 44% and for SYCL it’s 35%. SYCL’s performance on AMD is primarily affected by the adv and miniWeather tests but removing them increases performance to 81% with an SD of 19%. OpenMP’s issue is spread across all benchmarks.
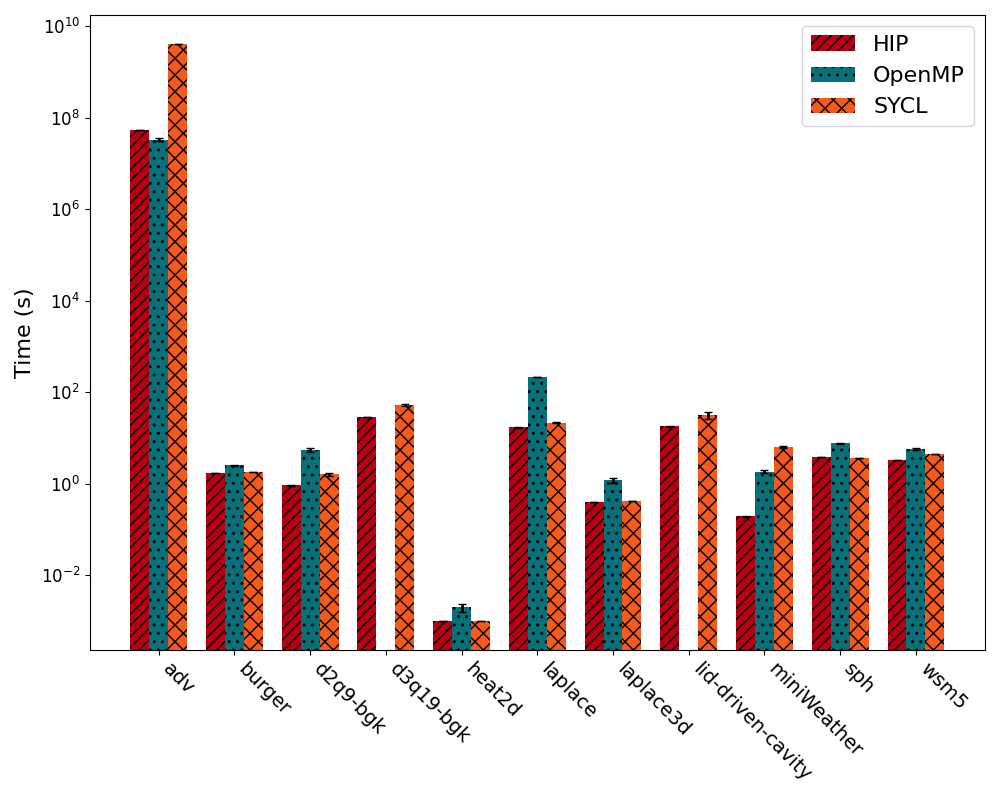
Figure 2: AMD RX 6700 XT performance comparison across HIP, OpenMP, and SYCL
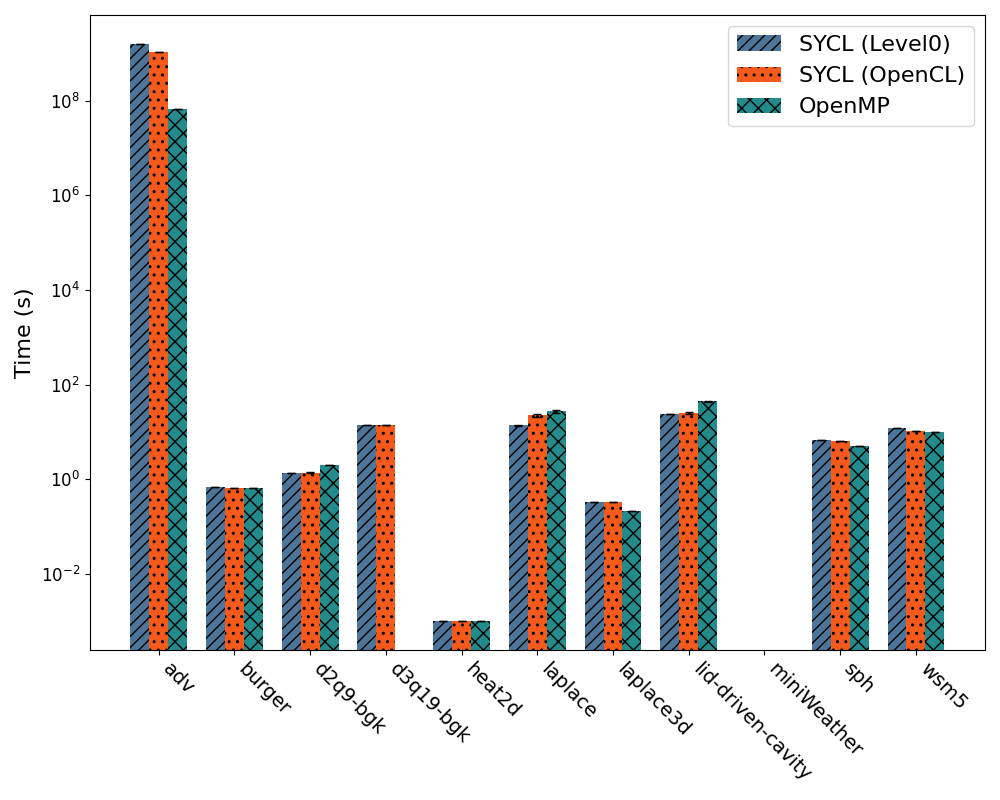
Figure 3: Intel Max 1100 performance comparison across SYCL(Level0), SYCL(OpenCL), and OpenMP
Finally, the Intel Max 1100 results are shown in Figure 3. SYCL runs on two backends: Level0 and OpenCL, both maintained by Intel with no notable differences expected.
In this instance, all three implementations failed to execute the miniWeather benchmark because of MPI call incompatibilities in the system, unrelated to the languages used.
Regarding the numbers and SYCL, both backends are virtually equivalent in performance, achieving an average speedup of X1. Transitioning to OpenMP, it shows a slight speedup over the SYCL equivalents, averaging X1.05.
Conclusions
We evaluated portable language performance (OpenMP and SYCL) against native GPU languages (CUDA, HIP, Level0) on three major vendors’ GPUs (NVIDIA, AMD, Intel).
In NVIDIA GPUs, both alternatives achieved approximately 89-90% of native performance. In AMD systems, SYCL reached 81%, while OpenMP only achieved 51%. Across all implementations on Intel accelerators, similar results with no significant degradation were observed.
These results show the potential of using open, multi-device languages to improve parallel CFD development, boosting performance and cutting down on development and maintenance time.
References
[1]: https://doi.org/10.1145/3529538.3529980
[2]: https://doi.org/10.1016/j.jcp.2014.08.024
Resources
The blog code is freely available at: https://github.com/A924404/cfd-bench
This blog article was written by our partner Atos.
Stay tuned for more articles on computational fluid dynamics.