Authors: Shubham Kavane, Kajol Kulkarni, Prof. Dr.-Ing. Harald Köstler
Chair for Computer Science – System Simulation
Friedrich-Alexander University Erlangen-Nuremberg, Germany
shubham.kavane@fau.de
Motivation
Optimizing aerodynamic designs, such as vehicle shapes to minimize drag and enhance fuel efficiency, is a critical priority for automotive and aerospace industries. Effective aerodynamic optimization directly influences performance, sustainability, and operational costs, making rapid and precise design iterations essential. Traditionally, Computational Fluid Dynamics (CFD) simulations are utilized to provide detailed, highly accurate predictions of fluid behavior around structures. These simulations solve complex fluid flow equations numerically, offering invaluable insights into airflow interactions, turbulence, and potential areas for design improvements.
However, despite their accuracy and widespread usage, traditional CFD methods are computationally expensive, often requiring extensive computational resources and considerable processing time. Typical simulations can take hours or even days, making rapid iterative processes infeasible and thus significantly slowing down the overall design optimization pipeline [ES+06; MM98]. This limitation restricts engineers to fewer design iterations, potentially hindering innovation and delaying product development. To address these challenges, there is a pressing need for faster yet reliable modeling approaches—such as deep learning-based surrogate models—that enable quicker design cycles without sacrificing prediction quality.
Limitations of Traditional CFD Methods
Traditional Computational Fluid Dynamics (CFD) simulations are composed of several sequential steps, including detailed geometry creation, mesh generation, solver configuration, simulation execution, and subsequent analysis of the results. Each step in this workflow is resource-intensive and involves considerable computational effort. Geometry design and mesh generation are particularly time-consuming, as they involve meticulous discretization of complex geometries to ensure numerical accuracy. The solver setup itself requires careful selection and fine-tuning of numerical parameters, which further prolongs the preparation phase [Núñ+05; HKB07].
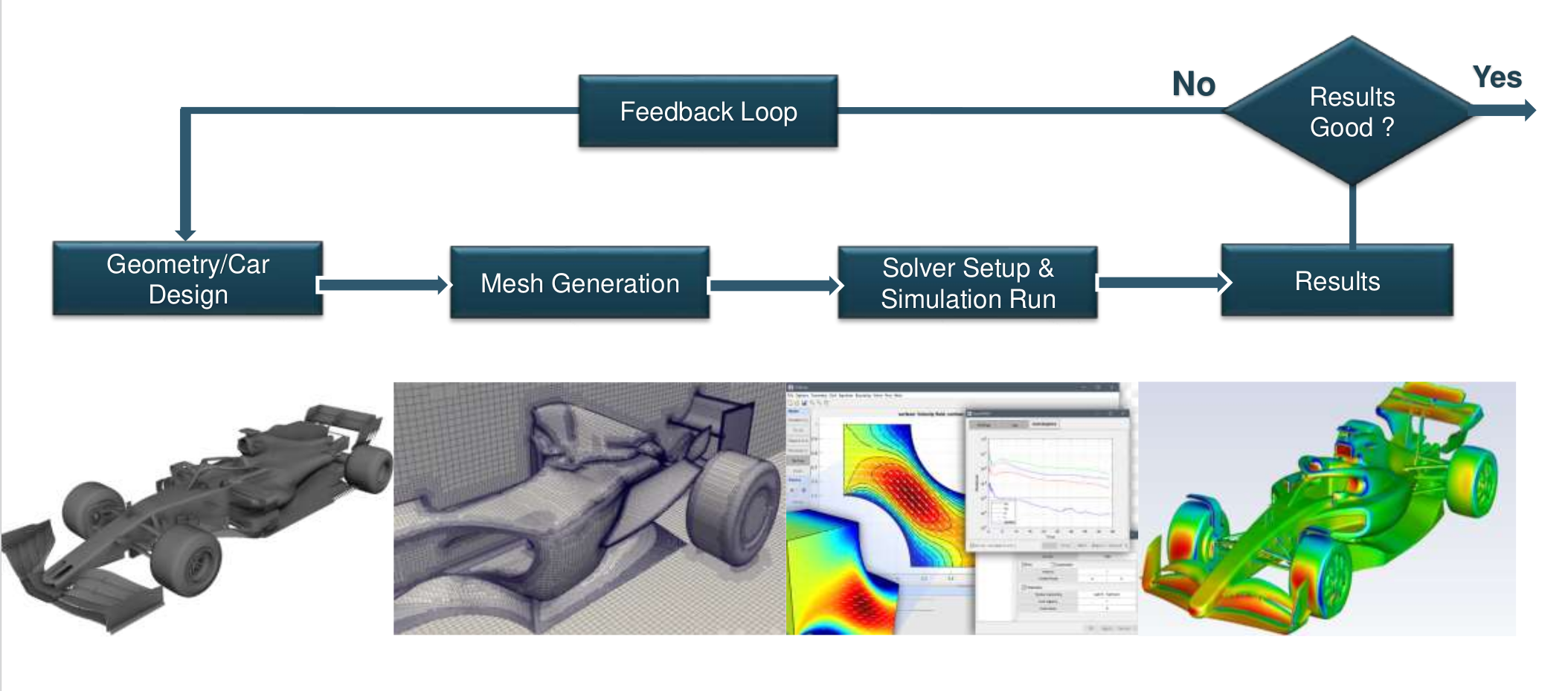
Moreover, the actual execution of these simulations, particularly for intricate flow scenarios or turbulent regimes, can take several hours or even days. Following simulation completion, engineers must conduct detailed analyses to validate results before making any iterative design adjustments. Such extended runtimes significantly limit the practicality of CFD methods in rapid iterative design optimization processes, effectively restricting the number of feasible design iterations within a given project timeline. Consequently, traditional CFD methods, despite their high precision, become a bottleneck in dynamic and time-sensitive engineering workflows, making iterative optimization processes slow, resource-intensive, and often impractical.
Deep Learning-Based Surrogate Models
To effectively address the inherent limitations of traditional CFD simulations, we propose adopting deep learning (DL)-based surrogate models. These surrogate models, trained on comprehensive datasets derived from CFD simulations, leverage powerful neural network architectures to rapidly approximate complex fluid flow behaviors. Unlike conventional CFD approaches, which require lengthy computations for every new design, surrogate models can produce high-quality predictions almost instantaneously, significantly cutting down the iterative cycle time [KA20; Zhu21].
Implementing DL-based surrogate models facilitates swift and efficient design iterations, dramatically accelerating the path towards optimized aerodynamic shapes. Engineers can rapidly evaluate numerous design scenarios within minutes, enabling extensive exploration of the design space and promoting innovation. By reducing computational overhead and turnaround time, surrogate models not only enhance productivity but also substantially lower computational costs and resource consumption, ultimately streamlining and energizing the entire design optimization process [Thu+20].
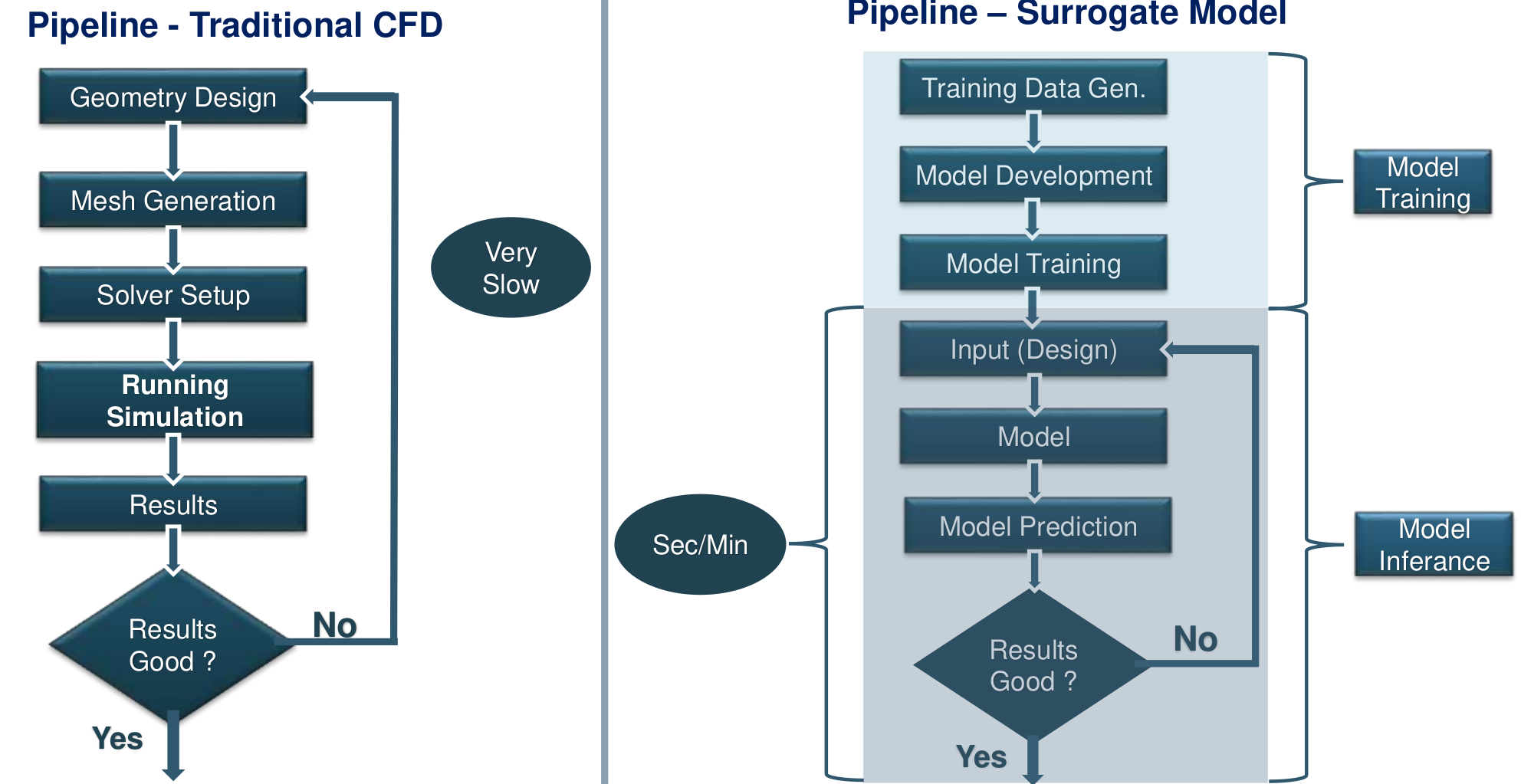
Data Generation and Simulation Setup
The training dataset for our advanced surrogate model consists of carefully crafted simulations representing realistic three-dimensional (3D) channel flow scenarios. These scenarios feature randomly generated geometrical obstructions, strategically placed within the flow domain to emulate complex real-world fluid dynamics situations. Such random variations in obstruction geometry ensure that the model learns robust, generalizable flow characteristics rather than specific, predefined scenarios, enhancing its predictive capability across diverse fluid flow configurations. The external stakeholder SLB-analys, a unit of the Environment and Health Administration of the City of Stockholm provided data for the simulations through a collaboration with ENCCS, the EuroCC National Competence Center Sweden.
To accurately simulate fluid behavior around these geometries, we utilized the Lattice Boltzmann Method (LBM) within the robust computational framework, waLBerla. LBM, renowned for its efficiency in handling complex flow phenomena, was chosen due to its computational effectiveness and precision in modeling intricate flow interactions at small scales. Additionally, object shapes within the simulations were precisely captured using Signed Distance Fields (SDF). SDF provides a smooth and computationally efficient mathematical representation of geometrical shapes, facilitating accurate modeling of object-fluid interactions, enhancing simulation accuracy, and subsequently improving the fidelity and relevance of the training dataset for deep learning applications.

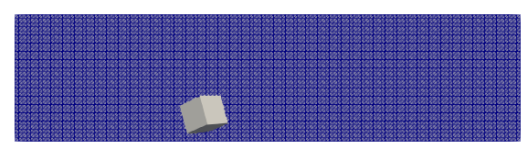
Figure 3: Input to the Deep Learning Model – Geometry (SDF). The input geometry is derived from an .stl file, which is then converted into a Signed Distance Field (SDF) representation to effectively model both the flow field and the object. [Kul]
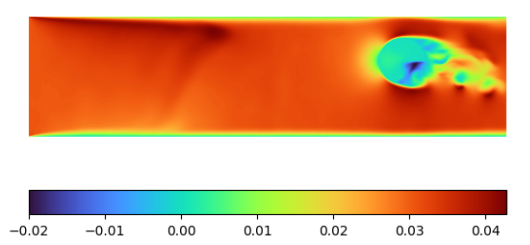
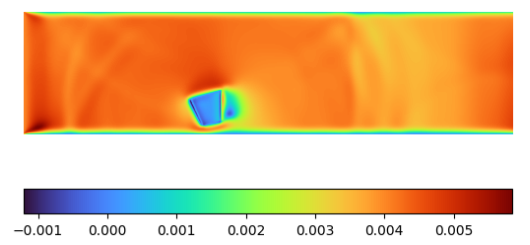
Figure 4: Sample output expected from the Deep Learning model. The ground truth is generated using waLBerla, an LBM-based framework, ensuring accurate fluid flow simulations for model training and evaluation. [Kul]
Advanced U-Net Architecture: Enhancements and Improvements
Initially, our approach employed a standard U-Net architecture for fluid flow prediction. While the U-Net demonstrated the ability to capture basic flow patterns, it exhibited notable limitations in accurately reconstructing complex flow structures, particularly in turbulent regimes. The standard U-Net struggled with retaining fine-grained spatial details and exhibited relatively high prediction errors in critical regions where fluid interactions were most intricate. These limitations necessitated substantial architectural enhancements to improve both predictive accuracy and computational efficiency.
To address these challenges, we introduced a series of key refinements to develop an advanced U-Net architecture tailored for high-fidelity fluid flow prediction. Firstly, we significantly deepened the network by increasing the number of encoder and decoder layers from 6 to 11, enhancing the model’s capacity to extract hierarchical features. Additionally, we expanded the number of channels up to 4096, allowing the network to encode richer feature representations across different scales. To further strengthen the model’s ability to learn multi-scale flow structures, we incorporated varying kernel sizes in the convolutional layers, enabling the extraction of both fine and coarse spatial patterns effectively.
Moreover, we integrated skip connections within encoder-decoder blocks to mitigate information loss during downsampling and upsampling operations, ensuring the preservation of critical spatial details throughout the network. Recognizing the need for improved feature selection, we also incorporated the Convolutional Block Attention Module (CBAM) [Woo+18], which adaptively refines feature maps by selectively focusing on the most informative spatial and channel-wise regions. This enhancement improves the model’s ability to distinguish between dominant and subtle flow features, leading to sharper and more
accurate flow predictions.
By implementing these refinements, our advanced U-Net architecture demonstrates superior performance over the standard model, effectively capturing intricate flow dynamics while maintaining computational efficiency. These improvements play a crucial role in bridging the gap between traditional physics based simulations and modern deep learning-driven surrogate models, enabling rapid and accurate fluid flow predictions.
Model Training and Performance
Due to the immense complexity and size of our advanced U-Net surrogate model, comprising approximately 511 million parameters, conventional training methods on a single GPU proved infeasible due to memory constraints and computational limitations. To address this, we implemented a sophisticated training strategy leveraging PyTorch’s Distributed Data Parallel (DDP) framework combined with Deep-Speed ZeRO-3 optimization. PyTorch DDP efficiently distributed computational loads across multiple GPUs, enabling simultaneous processing of data batches, significantly reducing training time while ensuring optimal resource utilization [FSD23].
DeepSpeed ZeRO-3 further optimized the training process by enabling effective model parallelism—efficiently distributing model parameters and gradients across multiple GPUs, thereby drastically reducing GPU memory usage [Dee23]. Our training infrastructure, utilizing eight NVIDIA A100 GPUs, allowed us to
overcome the memory bottleneck and train our complex model rapidly and effectively. These strategic enhancements resulted in a substantial performance gain, with our advanced model demonstrating a remarkable 71 percent reduction in relative L1 loss compared to the baseline U-Net model. This notable improvement highlights the model’s capability to deliver significantly more accurate fluid dynamics predictions, marking a clear step forward in computational efficiency and predictive precision for fluid flow simulations.
Sample Results and Analysis: Performance Evaluation of the Advanced U-Net Model
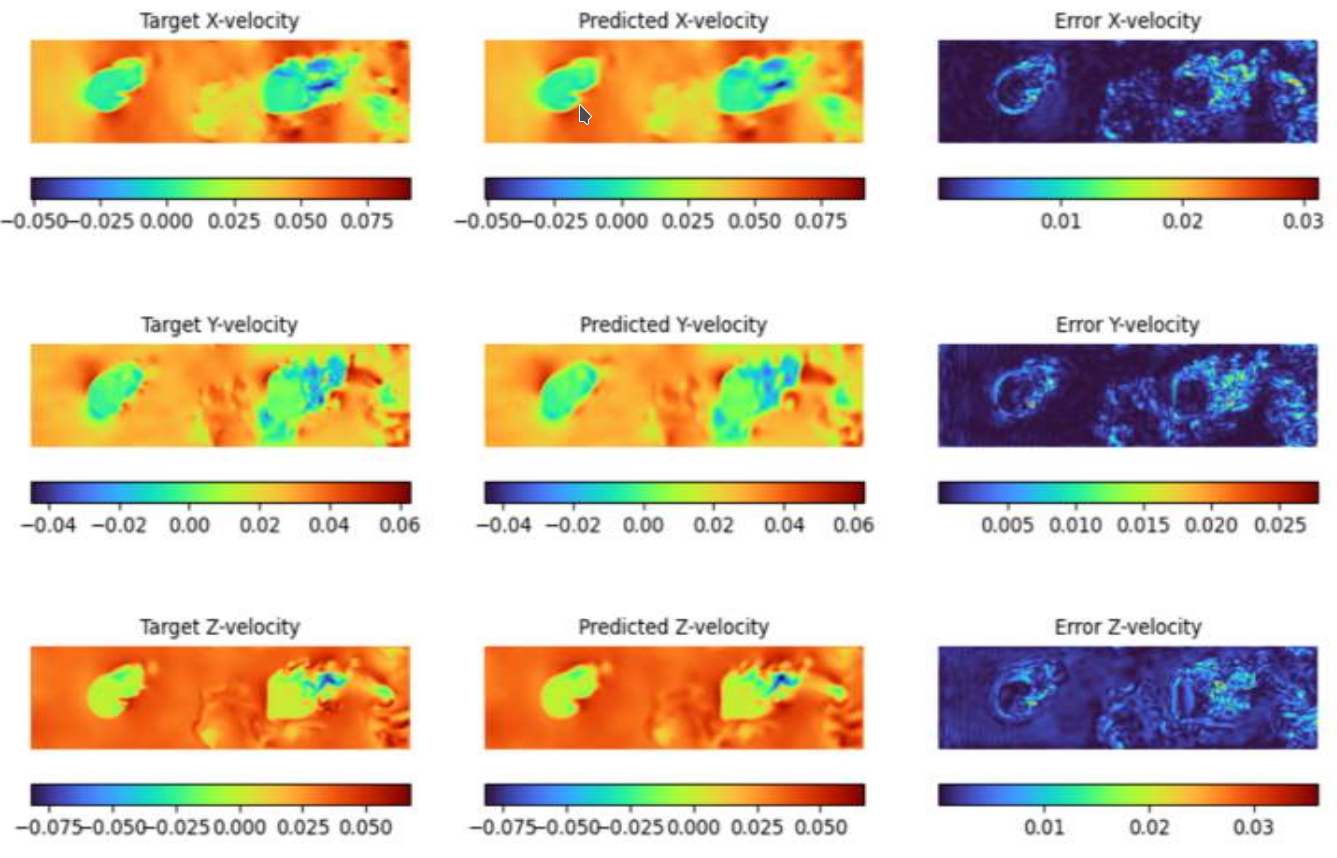
A comprehensive evaluation of the advanced U-Net model was conducted by comparing its predictive accuracy against the standard U-Net model. The primary metric used for assessment was the relative L1 norm error, which quantifies the deviation between predicted and ground truth velocity fields across different velocity components (X, Y, and Z directions). The results clearly indicate substantial performance improvements with the advanced U-Net architecture.
The standard U-Net exhibited relatively high prediction errors, particularly in complex flow regions where intricate turbulence structures exist. For instance, in the X-component of velocity, the standard U-Net yielded a relative L1 norm error of 0.02789, whereas the advanced U-Net significantly reduced this error to 0.008367, achieving a 70 percent improvement. Similar trends were observed in the Y-component, where the error decreased from 0.04285 to 0.010855, resulting in a 75.13 percent improvement. The Z-component showed a substantial enhancement as well, with the error dropping from 0.06850 to 0.02185, corresponding to a 68.10 percent improvement.
These results highlight the effectiveness of the architectural enhancements in the advanced U-Net, particularly the increased depth, expanded channel capacity, multi-scale kernel sizes, skip connections, and attention mechanisms. The significant error reduction demonstrates the model’s ability to capture complex fluid dynamics more accurately, effectively reconstructing fine-scale turbulence structures that the standard U-Net struggled to predict.
Overall, the advanced U-Net’s superior accuracy not only validates the necessity of its architectural refinements but also establishes it as a powerful and efficient surrogate model for fluid dynamics applications. These improvements pave the way for rapid and reliable aerodynamic design optimizations, bridging the gap between traditional CFD methods and real-time deep learning-based solutions.
Conclusion
The developed advanced U-Net-based surrogate model provides a transformative approach for predicting complex fluid flow behaviors, significantly reducing computational overhead compared to traditional CFD methods. By leveraging deep learning capabilities, the surrogate model rapidly delivers accurate flow predictions in seconds or minutes, as opposed to the extensive hours or even days typically required by conventional CFD simulations. This considerable acceleration in computational speed enables engineers to rapidly iterate through design modifications, facilitating more extensive exploration of innovative design options within shorter development cycles.
In practical terms, the surrogate model holds substantial promise for industries such as aerospace and automotive engineering, where aerodynamic optimization is vital. By drastically shortening prediction turnaround times, the advanced U-Net-based surrogate model empowers these industries to swiftly evaluate numerous design alternatives, achieving enhanced aerodynamic performance, reduced fuel consumption, and lower environmental impacts. Ultimately, this DL-based surrogate approach not only fosters innovation through faster iterative feedback but also significantly decreases the costs associated
with computational resources, positioning itself as an indispensable tool for efficient and agile design processes.
Bibliography
[MM98] Parviz Moin and Krishnan Mahesh. “Direct Numerical Simulation: A Tool in Turbulence Research”. In: Annual Review of Fluid Mechanics 30.1 (Jan. 1998), pp. 539–578. doi: 10. 1146/annurev.fluid.30.1.539. url: https://api.semanticscholar.org/CorpusID: 14986531.
[Núñ+05] Isidoro I. Albarreal Núñez et al. “Time and space parallelization of the navier-stokes equa- tions”. In: Computational & Applied Mathematics 24 (2005), pp. 417–438. url: https : //api.semanticscholar.org/CorpusID:53522811.
[ES+06] Howard Elman, David Silvester, et al. “Finite Elements and Fast Iterative Solvers: With Applications in Incompressible Fluid Dynamics”. In: Article (Jan. 2006). University of Maryland, College Park; The University of Manchester.
[HKB07] C. W. Hamman, R. M. Kirby, and M. Berzins. “Parallelization and scalability of a spectral element channel flow solver for incompressible Navier Stokes equations”. In: Concurrency and Computation: Practice and Experience 19 (2007). Published online 3 April 2007 in Wiley InterScience (www.interscience.wiley.com), pp. 1403–1422. doi: 10.1002/cpe.1181. url: https://api.semanticscholar.org/CorpusID:263531276.
[Woo+18] Sanghyun Woo et al. “CBAM: Convolutional Block Attention Module”. In: ArXiv abs/1807.06521 (2018). url: https://api.semanticscholar.org/CorpusID:49867180.
[KA20] Asharul Islam Khan and Salim Al-Habsi. Machine Learning in Computer Vision. 2020. url: https://api.semanticscholar.org/CorpusID:264687186.
[Thu+20] Nils Thuerey et al. “Deep Learning Methods for Reynolds-Averaged Navier-Stokes Simulations of Airfoil Flows”. In: AIAA Journal 58.1 (2020), pp. 25–36. issn: 0001-1452, 1533-385X. doi: 10.2514/1.j058291.
[Zhu21] Chenguang Zhu. Deep learning in natural language processing. 2021. url: https://api. semanticscholar.org/CorpusID:234255733.
[Dee23] DeepSpeed. Getting Started with DeepSpeed. Accessed: 2023-12-18. 2023. url: https : / /deepspeed.readthedocs.io/en/latest/.
[FSD23] FSDPP yT orch. Getting Started with FULLY SHARDED DATA PARALLEL (FSDP). Ac- cessed: 2023-12-10. 2023. url: https://pytorch.org/docs/stable/fsdp.html.
[Kul] Kajol Kulkarni. Creating and Benchmarking Fluid Dynamics Dataset for Training Surrogate Model. url: https : / / www10 . cs . fau . de / publications / theses / 2023 / Master KulkarniKajol.pdf.
[Rac] Racecar Engineering. SimScale Webinar: Optimising racecars with CFD. https : / / www.racecar-engineering.com/articles/simscale-webinar-optimising-racecars-with-cfd/. Accessed: 18-Mar-2025.